KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2025 Vol. 24

Oxynizer: Non-electric oxygen generator for developing countries
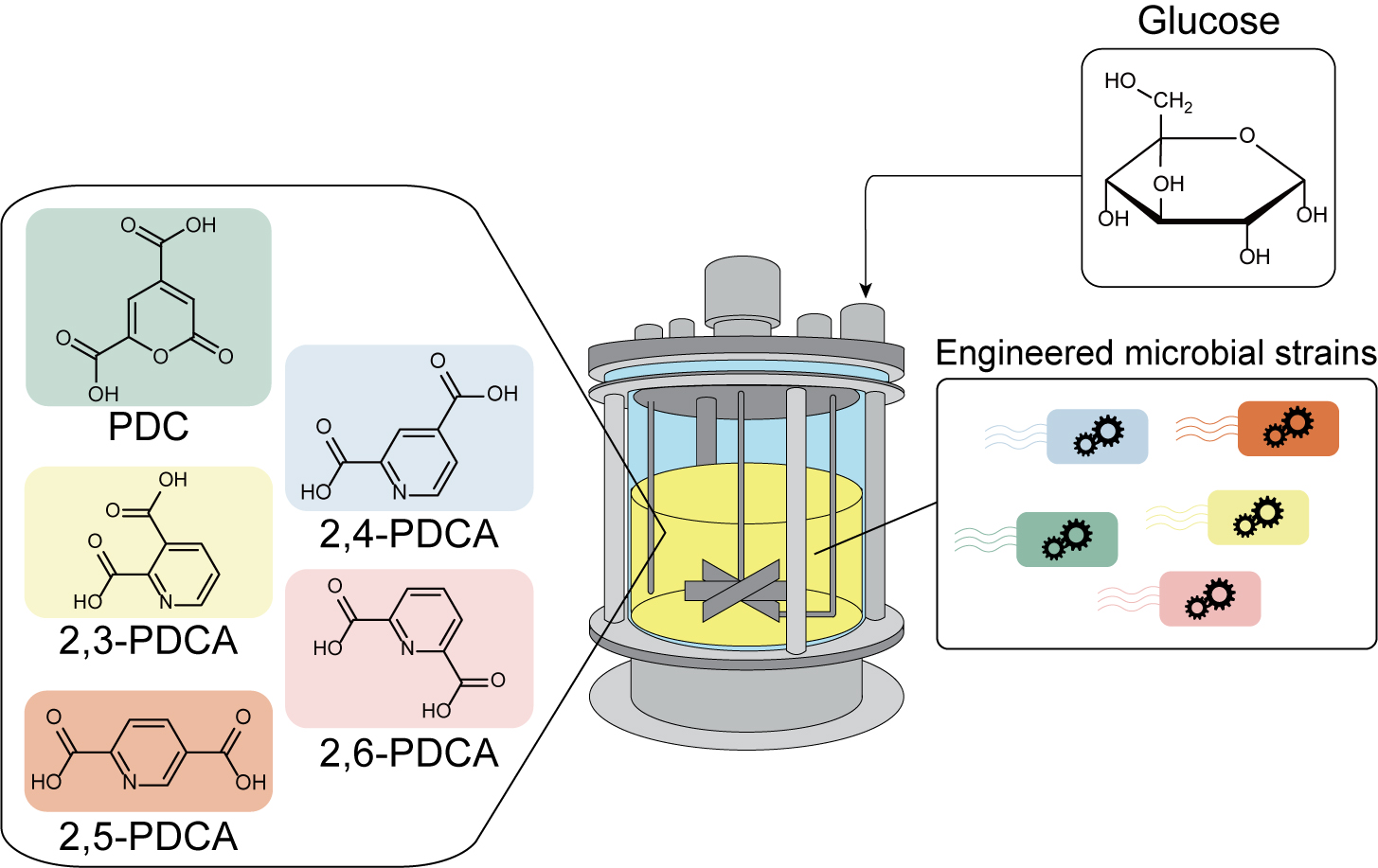
Microbial PET alternative plastic monomer production

Extending the lifespan of next-generation lithium metal batteries with water

Smart Warnings: LLM-enabled personalized driver assistance
Subscribe to our research webzine
Be the first to get the latest advancements in science and technology directly in your inbox.

Professor Ki-Uk Kyung’s research team develops soft shape-morphing actuator capable of rapid 3D transformations

When and why do graph neural networks become powerful?

Revolutionary analog computing chip that corrects its own error
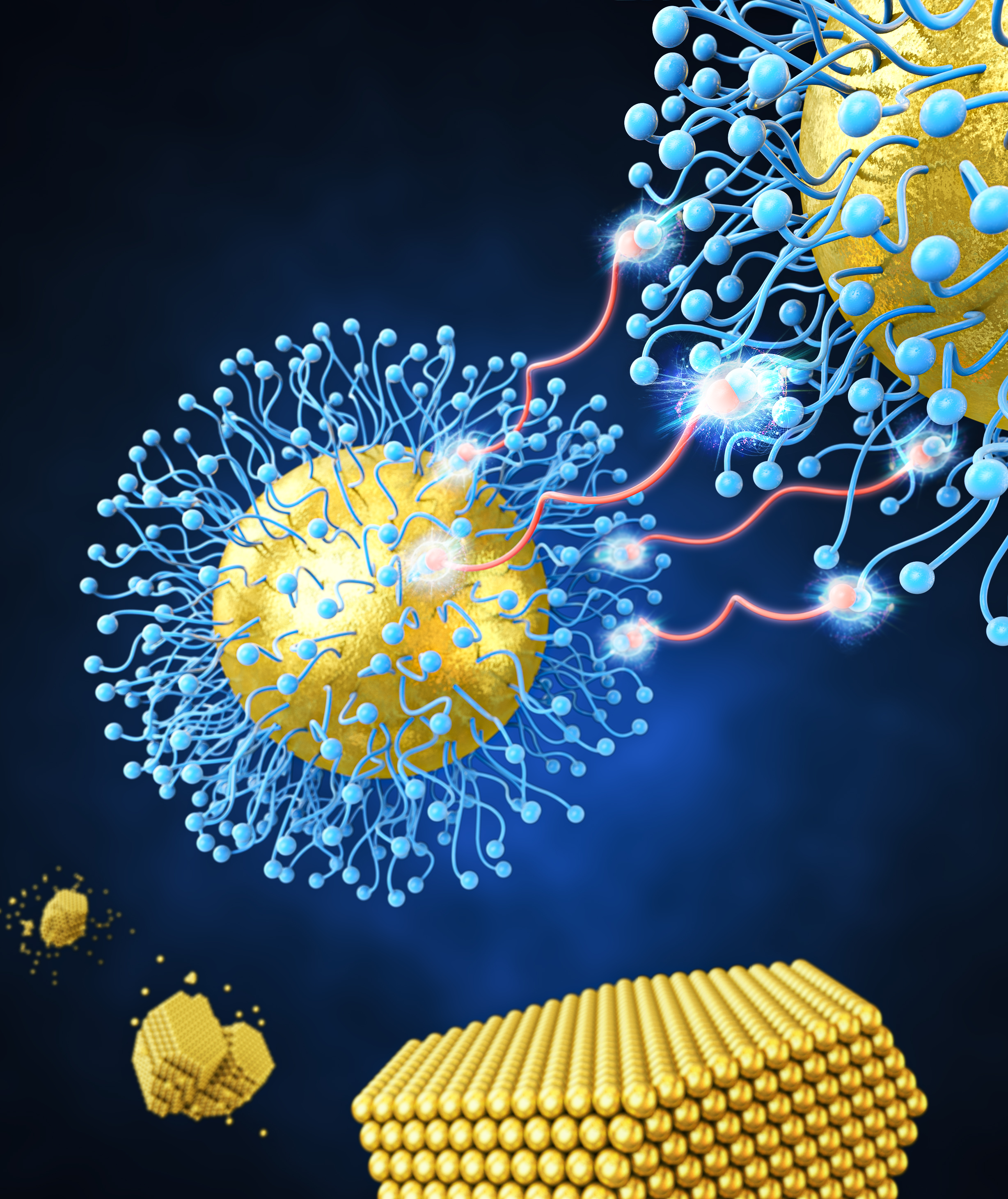
Development of a nanoparticle supercrystal fabrication method using linker-mediated covalent bonding reactions
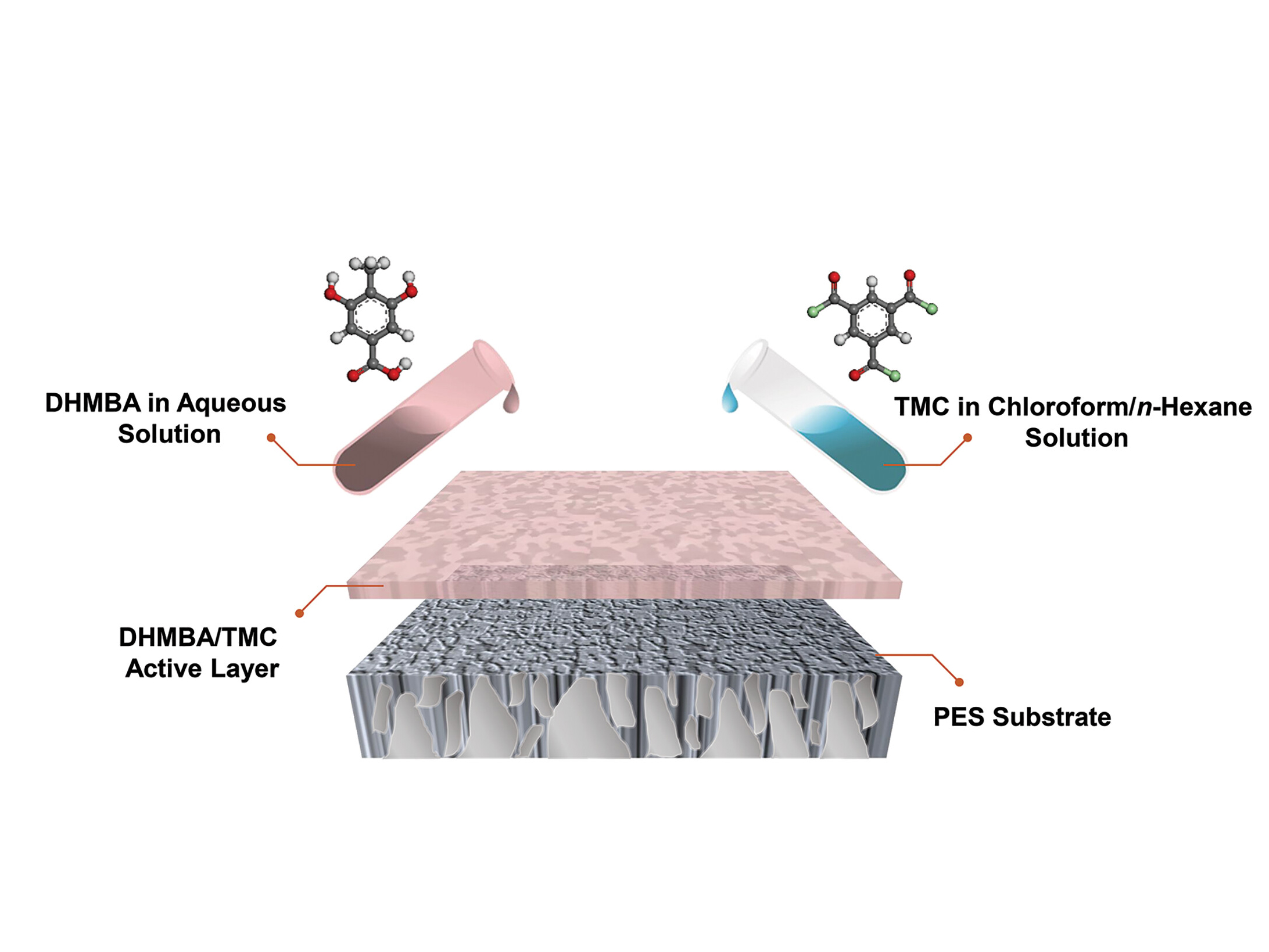
A Better membrane paves the way for broader access to clean water

A Drone-Multileg Robot team grabs objects on ship deck for 2024 MBZIRC Maritime Grand Challenge

Advanced OOD detection for secure and reliable AI applications
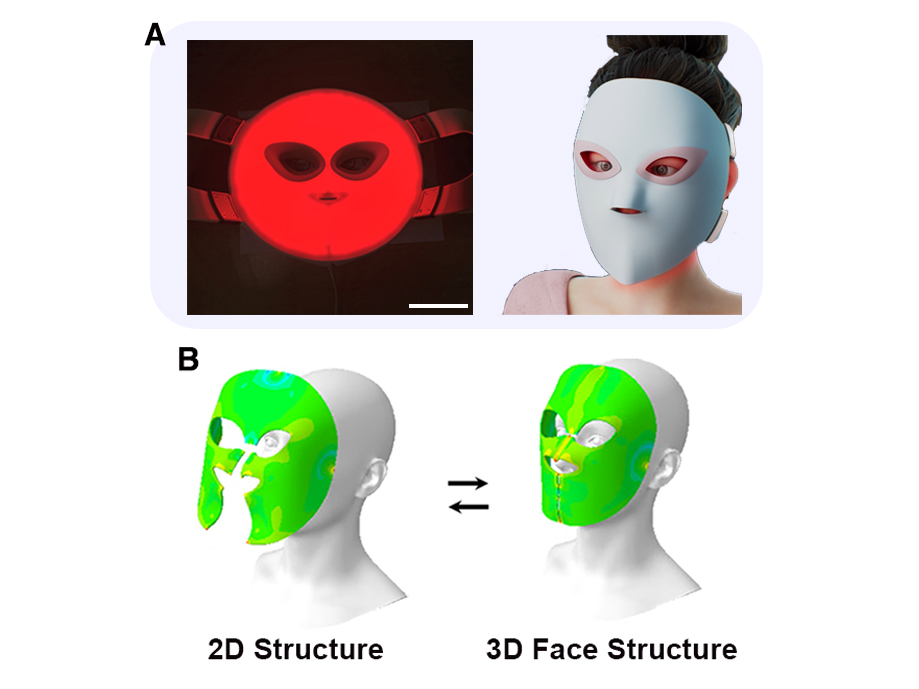
Face-conforming LED mask shows 340% improved efficacy in deep skin elasticity
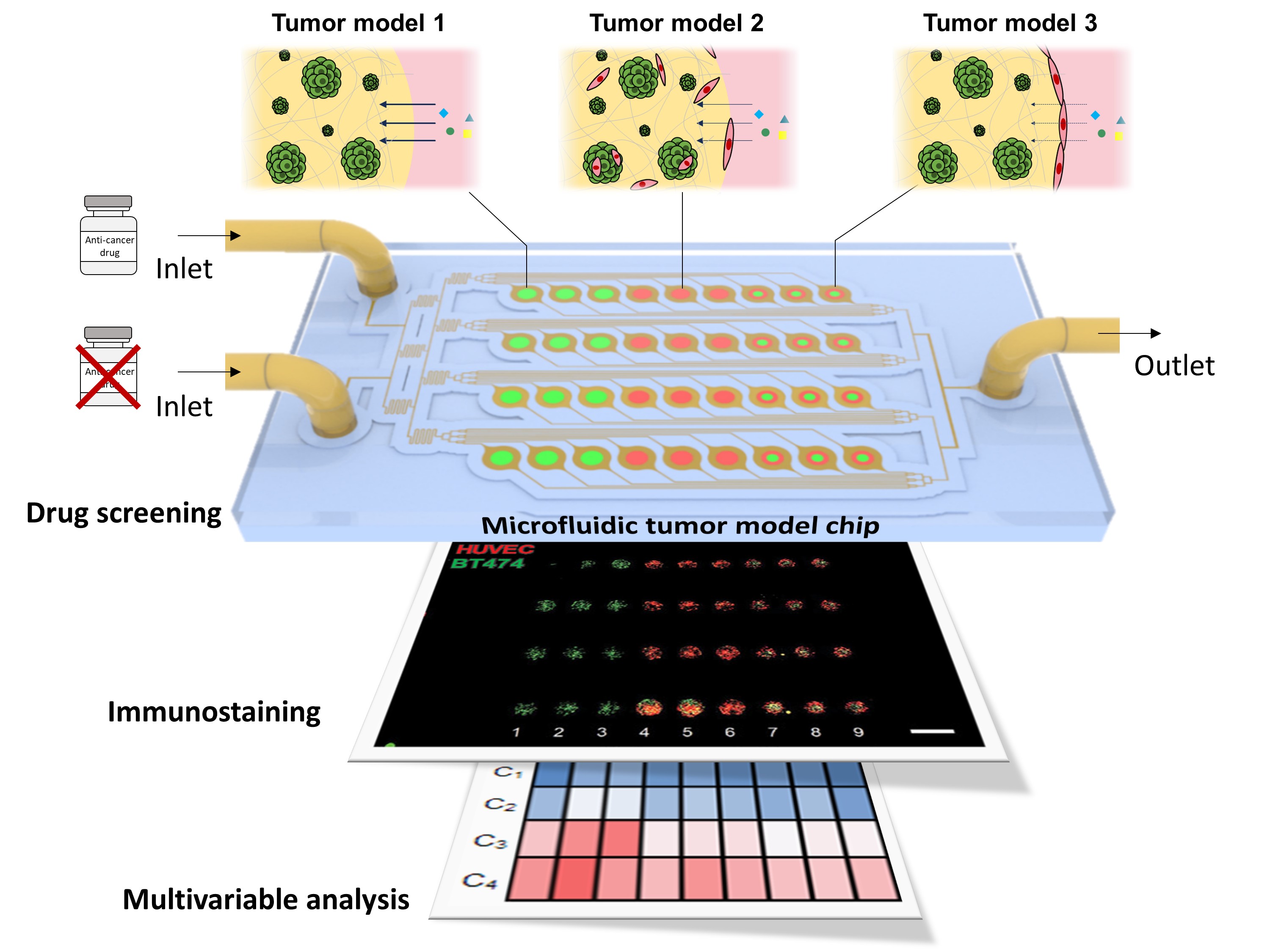
How tumor model chip Is revolutionizing anticancer drug testing
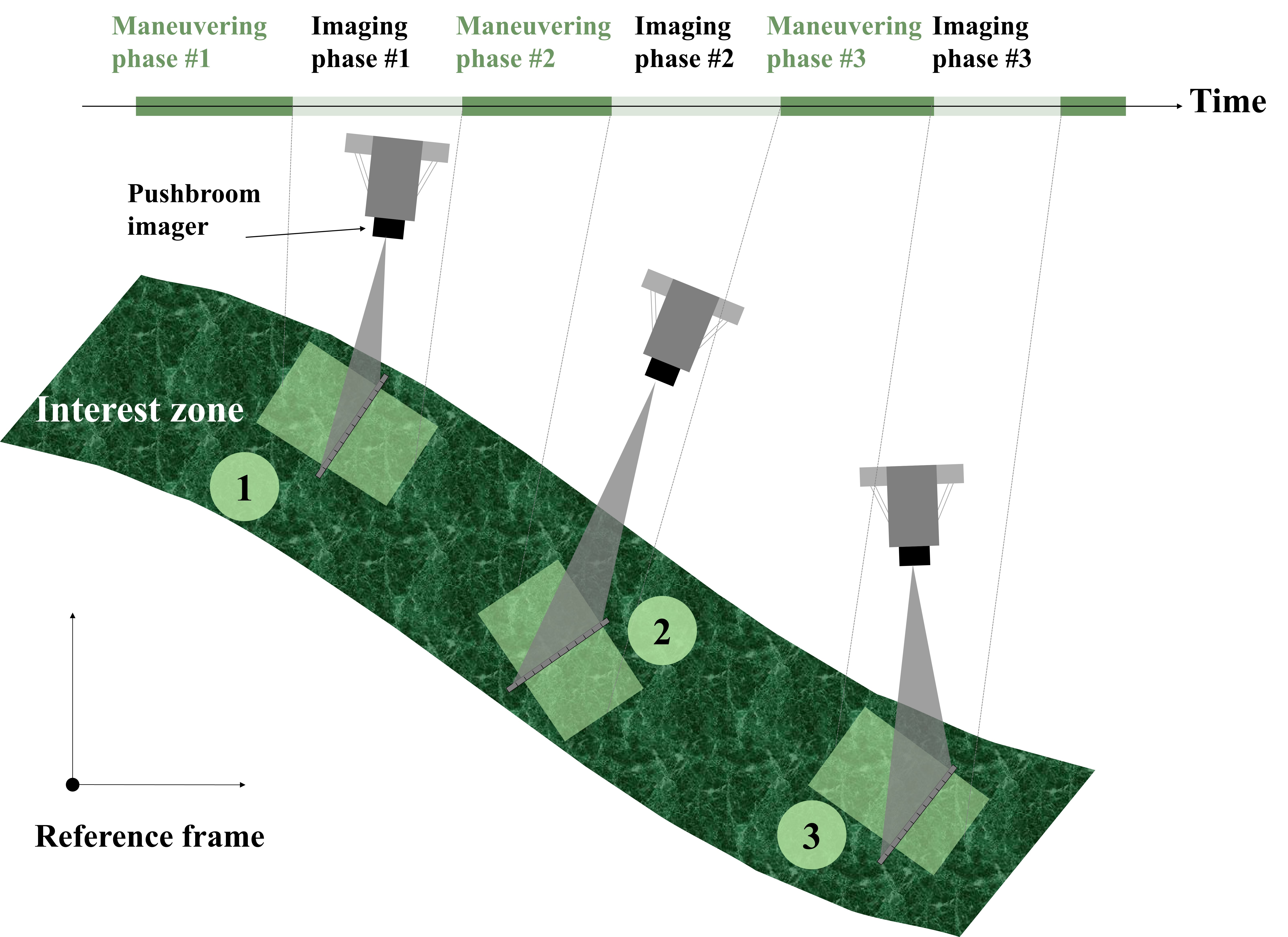
Recent advances in satellite attitude guidance technology for earth observation missions
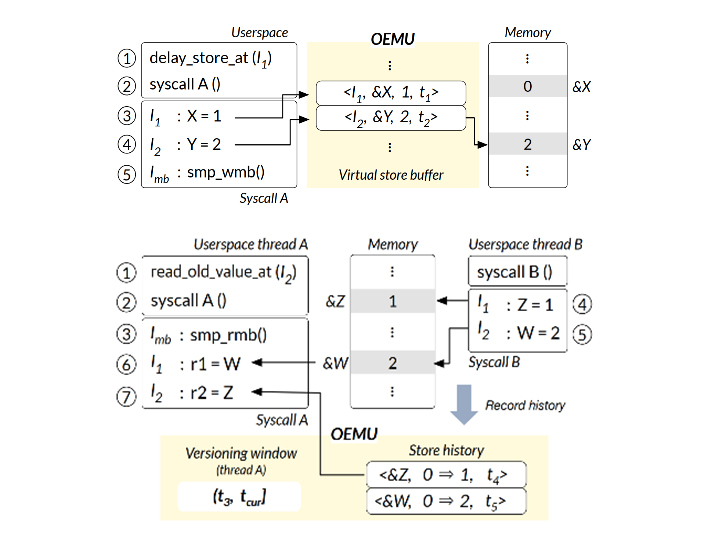
A new bug-finding system to Identify Kernel Out-of-Order Concurrency Bugs





