KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Fall 2025 Vol. 25Data-centric solutions for Responsible AI: fair data labeling and acquisition
Data-centric solutions for Responsible AI: fair data labeling and acquisition
Responsible AI problems like fairness need to be solved in a data-centric fashion as AI is only as good as its data. A fundamental solution is proposed by using fair data labeling and acquisition.
Article | Spring 2023
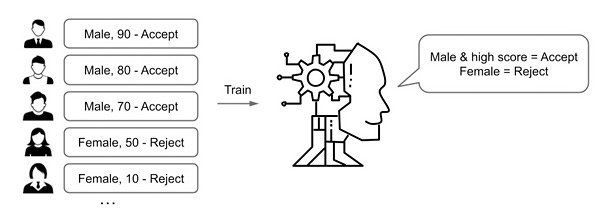
As AI has become more sophisticated, people may have felt nervous knowing that companies can use Artificial Intelligence (AI) to hire new recruits, only to find out that it is discriminating against certain people. While AI is becoming widespread and being applied to hiring processes and medical systems, the process and systems need to be fair so that AI does not put certain people at a disadvantage unnecessarily. The root cause of this unfairness is the biased data that is used to train the AI. Suppose an AI is trained to hire people as shown in Figure 1 where each person has a score that indicates his or her ability. If most of the training data consists of men, and there are few women with high scores, then high-scoring women may get rejected regardless of their scores because the AI model does not have much knowledge about women.
While most of the existing work has focused on improving the training algorithm (i.e., model-centric AI) to make the model robust against biased data, fixing the data itself (i.e., data-centric AI) before model training is the fundamental solution. In most settings where AI learns from labeled data (i.e., data with answers), the key issues are ensuring that the labels and data are unbiased. PhD student Ki Hyun Tae from the KAIST Data Intelligence Lab led by Prof. Steven Euijong Whang has pioneered this research and proposed groundbreaking solutions for fixing labels (ACM SIGMOD 2023; top Database conference) and acquiring data (ACM SIGMOD 2021) among other contributions.
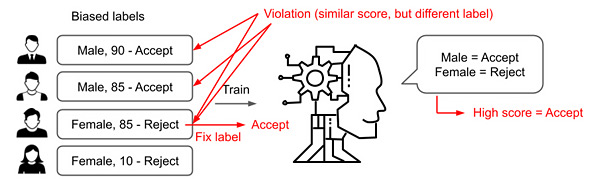
The first work iFlipper [1] fixes labels to improve individual fairness where similar people should have similar predictions. Specifically, iFlipper minimally flips labels to reduce fairness violations, where a violation can occur when two similar people are labeled differently. In Figure 2, there are two violations among the first three people – (first, third) and (second, third) – because only the third person is rejected despite having a similar score as the first two, possibly due to biased hiring in the past. After flipping (i.e., fixing) the third person’s label to an accept, there is no violation. Solving this problem efficiently on large data is difficult, and iFlipper provides an approximate algorithm with theoretical guarantees.
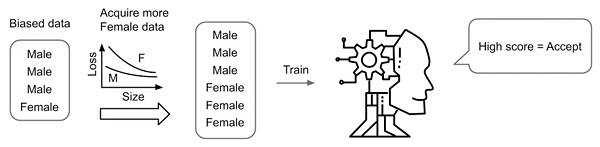
The second work Slice Tuner [2] fixes the data for fair and accurate models using selective data acquisition. The goal is to ensure similar prediction accuracies among different groups (also called slices) of people. Simply acquiring large amounts of data is not necessarily a good solution as it may worsen the bias in data. Figure 3 illustrates this point where, if there is enough data for men, but not enough data for women, then acquiring more female data is better for fairness. Slice Tuner determines how much data should be acquired for each group to maximize both fairness and accuracy. The key idea is to use learning curves, which estimate model accuracies when more data is given per group. Since learning curves are initially unreliable and change as data is acquired, Slice Tuner updates them iteratively when necessary.
The research team believes the two studies along with other contributions by Ki Hyun (data cleaning [3] and finding discriminated groups [4,5]) are important foundations towards realizing a Responsible AI from a data-centric perspective.
References
[1] H. Zhang*, K. Tae*, J. Park, X. Chu, and S. E. Whang, iFlipper: Label Flipping for Individual Fairness. Accepted to 2023 ACM SIGMOD Int’l Conf. on Management of Data. (*: Equally Contributed; Top Database conference)
[2] K. Tae and S. E. Whang, Slice Tuner: A Selective Data Acquisition Framework for Accurate and Fair Machine Learning Models. In Proc. 2021 ACM SIGMOD Int’l Conf. on Management of Data. (Top Database conference)
[3] K. Tae, Y. Roh, Y. Oh, H. Kim, and S. E. Whang. Data Cleaning for Accurate, Fair, and Robust Models: A Big Data – AI Integration Approach, In 3rd Int’l Workshop on Data Management for End-to-End Machine Learning @ 2019 ACM SIGMOD.
[4] Y. Chung, T. Kraska, N. Polyzotis, K. Tae, and S. E. Whang. Slice Finder: Automated Data Slicing for Model Validation, In IEEE Int’l Conf. on Data Engineering, 2019. (Top-3 Database conference)
[5] Y. Chung, T. Kraska, N. Polyzotis, K. Tae, and S. E. Whang. Automated Data Slicing for Model Validation: A Big data – AI Integration Approach, In IEEE Transactions on Knowledge and Data Engineering, 2020. (Top Database journal)
Most Popular

A New solution enabling soft growing robots to perform a variety of tasks in confined spaces
Read more
Towards a more reliable evaluation system than humans - BiGGen-Bench
Read more
Development of a compact high-resolution spectrometer using a double-layer disordered metasurface
Read more
AI-Designed carbon nanolattice: Feather-light, steel-strong
Read more
Dual‑Mode neuransistor for on‑chip liquid‑state computing
Read more