KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2025 Vol. 24Understanding the meaning of pixels is fundamental in building a visual intelligence but often involves costly labeling. This work proposes an AI that can learn any pixel-labeling task using only a few labeled images.
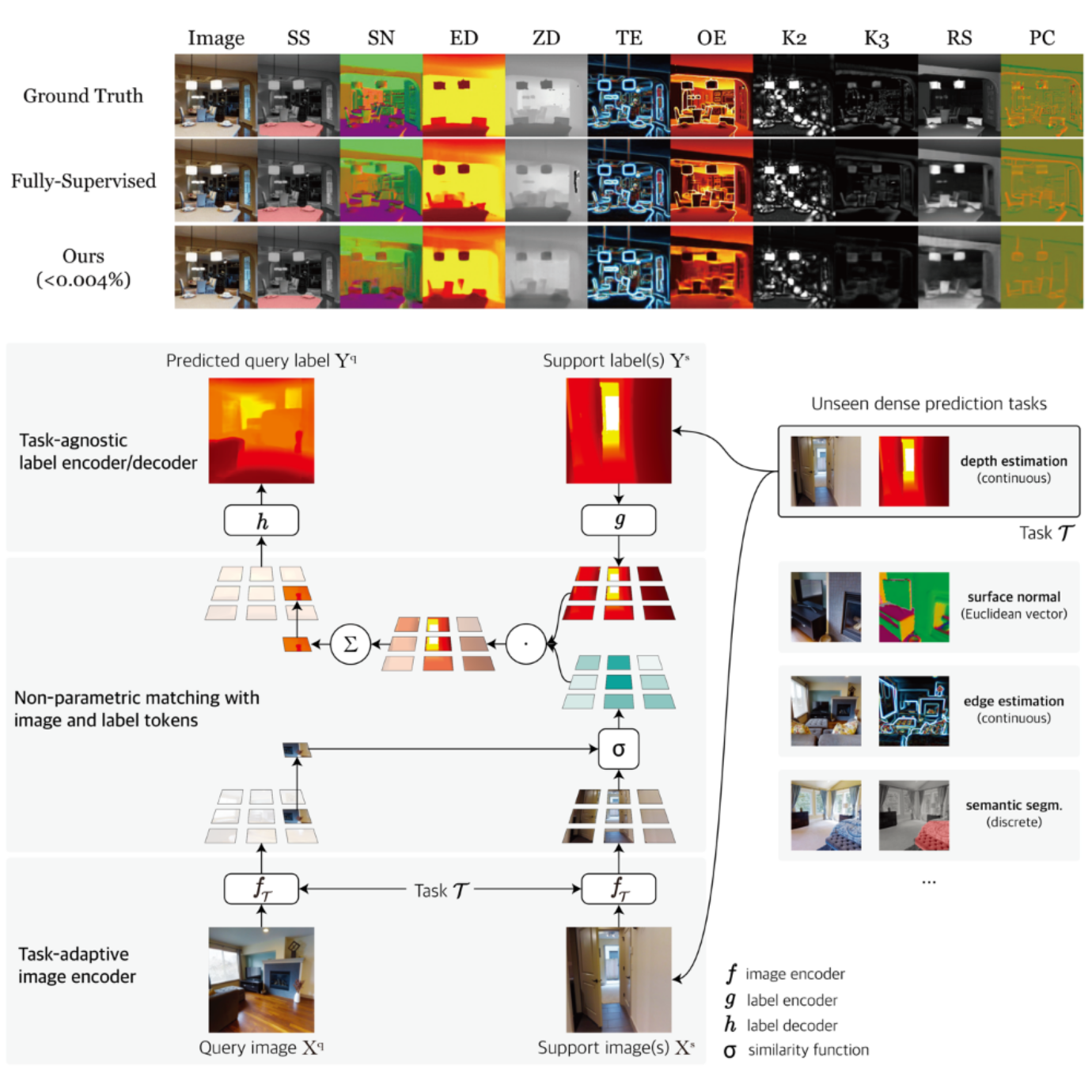
The fundamental of building a visual intelligence is understanding the pixels. Given complex patterns of visual signals such as images, it is important to understand high-level meanings of every pixels, such as object categories, distance to the camera, orientation of the surface, velocity of motion, and boundary of the objects. All these problems relate to associating labels to the pixels, and are often referred to as dense prediction problems. As the name suggests, dense prediction broadly encapsulates many computer vision problems, often referred in different names depending on types of labels, such as object segmentation, object detection, pose estimation, depth estimation, and motion estimation.
The key challenge to the dense prediction is collecting training data. In order to teach AI to infer per-pixel labels, each training image should be also have every pixel labeled. This per-pixel labeling is often too laborious and costly, putting major bottlenecks to building visual AI. Previous studies that attempted to reduce the need for labeled data have typically still demanded a substantial amount of such data, or they have concentrated on a particular group of tasks. The lack of a data-efficient, general-purpose AI for dense prediction tasks has led to limited applications in real-world computer vision problems, particularly in scenarios where available data is scarce.
A research team led by Professor Seunghoon Hong from the School of Computing at KAIST has developed a novel framework that can efficiently learn arbitrary dense prediction tasks using only a small amount of labeled data. Their pioneering work was not only published but also honored with the Outstanding Paper Award at the 2023 International Conference on Learning Representations (ICLR), a premier conference in the fields of artificial intelligence and machine learning. Based on the Google Scholar h5-index, ICLR ranks first in the artificial intelligence category, and stands at 9th position across all categories, underscoring its significant academic influence. The awarded paper stood out as one of the top four out of the 1574 papers published at the conference.
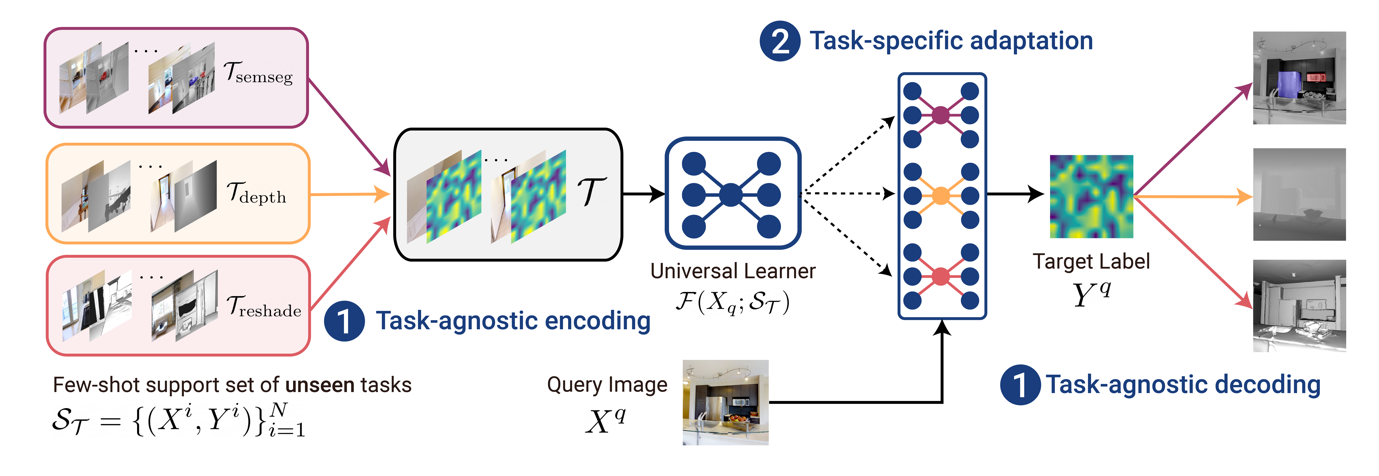
The core principle of this research lies in unifying the learning mechanism that is inspired by how humans solve a new task – analogy-making. To solve a new task, the method first extracts local representations from a query image and a few given labeled images, then compares how similar they are. Based on the similarities, the method makes an analogy to the query image by combining the given labels, assigning greater weight to those that are more similar. This mechanism, named Visual Token Matching (VTM), is designed to address a variety of dense prediction tasks in a unified manner. Moreover, VTM has a flexible and data-efficient adaptation mechanism that allows it to learn various notions of similarity for the analogy making, which is crucial to solve different types of dense prediction tasks.
Most Popular

When and why do graph neural networks become powerful?
Read more
Smart Warnings: LLM-enabled personalized driver assistance
Read more
Extending the lifespan of next-generation lithium metal batteries with water
Read more
Professor Ki-Uk Kyung’s research team develops soft shape-morphing actuator capable of rapid 3D transformations
Read more
Oxynizer: Non-electric oxygen generator for developing countries
Read more