KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2025 Vol. 24New big data clustering algorithm with high accuracy and efficiency
New big data clustering algorithm with high accuracy and efficiency
When analyzing big data, it is usually difficult to achieve both accuracy and efficiency. If you emphasize efficiency (or accuracy), accuracy (or efficiency) would be sacrificed. However, through the development of an elegant and remarkably simple algorithm, Prof. Jae-Gil Lee’s team has solved for both simultaneously in k-medoids clustering.
Article | Spring 2018
Prof. Lee’s team is developing scalable data mining / machine learning algorithms in support of big data. The k-medoids algorithm is one of the best-known clustering algorithms. Many data mining textbooks introduce it after the k-means algorithm because both algorithms use the notion of representatives. In the k-medoids algorithm, the representatives – medoids – are always selected from actual data objects; on the other hand, in the k-means algorithm, the representatives are determined to be the means of data objects.
This is analogous to the difference between the median and mean in statistics. Therefore, the k-medoids algorithm is more robust to noises or outliers than the k-means algorithm because a medoid is less influenced by noises or outliers than a mean.
In addition, the k-medoids algorithm can be applied to a complex data type whose distance measure is not the Euclidean distance. Despite this comparative advantage, the k-medoids algorithm is not as widely used for big data analytics as the k-means algorithm mainly because of its high computational complexity. Although the k-means algorithm has linear time complexity with respect to the number of objects, the most common realization of k-medoids clustering – the Partitioning Around Medoids (PAM) algorithm – has quadratic time complexity. In fact, major distributed machine learning platforms such as Apache Mahout and Apache Spark MLlib officially support only the k-means algorithm between the two algorithms.

Therefore, the research team aimed to develop a ‘parallel’ k-medoids algorithm that guarantees not only high efficiency but also high accuracy. As in Figure 1, a parallel algorithm can be executed one piece at a time on many different machines and then combined together again at the end to get the correct result. The existing algorithm, PAM, incurs high computational cost because it performs a global search over entire data. They are the two main ingredients for high accuracy, but using them simultaneously reduces efficiency. Thus, as in Figure 2, the key idea is to apply these two components individually through two phases: parallel seeding and parallel refinement. In the first phase, the algorithm generates multiple random samples and runs a k-medoids algorithm (e.g., PAM), which performs a global search, on each sample in parallel.
Then, it selects the best among the sets of seeds, each of which is obtained from a sample, and feeds it to the next phase. The second phase aims at reducing the possible errors induced by sampling. The algorithm partitions the entire data based on the seeds and constructs initial clusters. Then, it updates the medoids in parallel locally at each of the initial clusters. The novelty of the algorithm lies in the smart integration of known techniques with formal justifications. The simplicity of the algorithm is a strong benefit because simple algorithms often make a big impact and gain widespread acceptance.
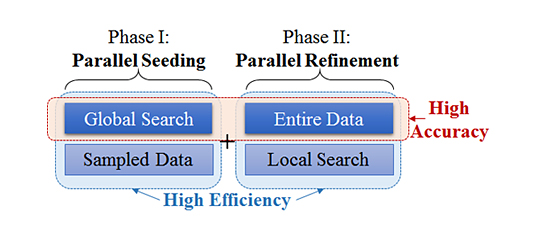
The research team conducted experiments on 12 Microsoft Azure D12v2 instances located in Japan. Each instance has four cores, 28 GB of main memory, and 200 GB of disk (SSD). All instances run on Ubuntu 14.04. Regarding accuracy, the clustering error is only 1.01~1.03 times that of the most accurate existing algorithm (PAM). At the same time, regarding efficiency, the elapsed time is as low as 52% of the fastest existing algorithm. Therefore, the proposed algorithm has been proven to achieve both high accuracy and high efficiency.
The algorithm was presented at KDD 2017, which is the top-tier conference in the field of data mining.
Original paper: https://dl.acm.org/citation.cfm?id=3098098
Promotion video: https://www.youtube.com/watch?v=muchytZNbkk&list=PLliTSxmRFGVPkvUZb3Q-DzvOgs20LOinA&index=78&t=3s
Source code: https://github.com/jaegil/k-Medoid
Most Popular

When and why do graph neural networks become powerful?
Read more
Smart Warnings: LLM-enabled personalized driver assistance
Read more
Extending the lifespan of next-generation lithium metal batteries with water
Read more
Professor Ki-Uk Kyung’s research team develops soft shape-morphing actuator capable of rapid 3D transformations
Read more
Oxynizer: Non-electric oxygen generator for developing countries
Read more