KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2025 Vol. 24Predicting the key actions that lead a robot to accomplish a task using deep learning
Predicting the key actions that lead a robot to accomplish a task using deep learning
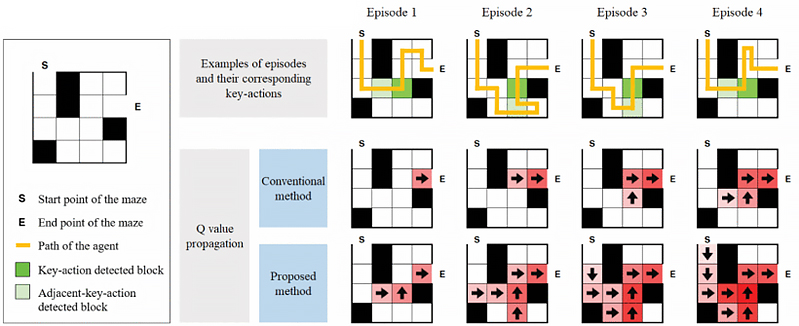
In reinforcement learning, a reinforcement signal may be infrequent and delayed, not appearing immediately after the action that triggered the reward. A novel method to detect the key action, defined as the most important action contributing to accomplishing a task, is proposed using deep neural networks. With the detected key action, rewards are re-assigned to the robot to improve its final success rate and convergence speed.
Article | Spring 2020
Recent advances in Artificial Intelligence, especially in the area of deep reinforcement learning, have been responsible for breakthroughs in fields that were extremely challenging for humans, such as in the strategy game Go, as in 2016 an AI system called AlphaGo won a best of five game match against the world champion Lee Sedol.
These advances were made possible by the rapid development of high-performance graphics processing units (GPU) that enabled the training of neural networks using large amounts of data. The success of deep reinforcement learning in classical deterministic games and video games environments, like Atari games and Starcraft 2, led to the rise in research teams trying to apply the technique to robotic manipulation tasks.
In some robotic applications, the robot finishes a task after completing a long sequence of actions. For example, it can take thousands of actions for the robot to solve a Rubik’s cube. Because of the long delay to receive feedback, the robot is not able to recognize which actions were the important ones leading to success.
A research team led by Professor Dongsoo Har from The Cho Chun Shik Graduate School of Green Transportation at the Korea Advanced Institute of Science and Technology developed a novel method to detect the most important action contributing to the accomplishment of a task by a robot arm. This action is defined as the key action leading the robot to success. The key action is detected based on a neural network model that tries to predict future outcomes in the system, such as the probability of accomplishing a task. With the result of the detection, positive feedback is then re-assigned to the key actions during the training of the deep reinforcement learning algorithm.
The research team used a robotic arm simulator to evaluate the performance of the prediction model for tasks while varying delay between the key action and the final result. The results showed that the assignment of feedback directly to the important actions improved the performance, reducing the number of failures, and affected the behavior of the robot (Figure 1). The research results indicates that an important factor for the development of future robotic systems, such as humanoid robots, using deep learning is the ability to predict future outcomes based on its current actions.
This study was published in IEEE Access (IEEE Access 2019, 7, 118776-118791).

Most Popular

When and why do graph neural networks become powerful?
Read more
Smart Warnings: LLM-enabled personalized driver assistance
Read more
Extending the lifespan of next-generation lithium metal batteries with water
Read more
Professor Ki-Uk Kyung’s research team develops soft shape-morphing actuator capable of rapid 3D transformations
Read more
Oxynizer: Non-electric oxygen generator for developing countries
Read more